
And why 4294967295 can be a sufficiently large number.
I’ve been learning a bit about data-oriented design, and have decideed to distill my findings into this blog post. I’ll leave a few links at the bottom that heavily inspired what I’ll share here.
Take a look at this motivating example:
// main.c
#include <stdio.h>
void increment_mut(int a) {
a += 1;
}
int main() {
int a = 4;
printf("a = %d\n", a);
increment_mut(a);
printf("a = %d\n", a);
}
If a programmer was using C for the first time and had used languages like Python or Java, they may expect a different output than what actually occurs:
λ :: gcc -o run main.c; ./run
a = 4
a = 4
After some digging, we learn that procedures copy arguments by value when pushing a frame onto the stack, so how are we supposed to mutate anything procedurally? Luckily, there is a solution. What if instead of having to determine what data is passed, you could pass a location to where there exists an instance of said data?
On most systems, probably including the one you are reading this on, pointers are represented as an unsigned 64-bit integer. Simplifying it in this manner neglects to admit the complexities of virtual memory and page tables but alas, for all practical purposes, that is handled by the OS and isn’t something we’ll talk about.
Great, now we have a canonical way to reference memory in terms of numbers. Now, if we wanted to ask ring 0 to apportion some memory of a certain size known at runtime, ring 0 can reply with an index that we can then use to find the memory later.
Reading from memory is terribly slow, and to demonstrate, we must look at the ground beneath us and understand our systems.
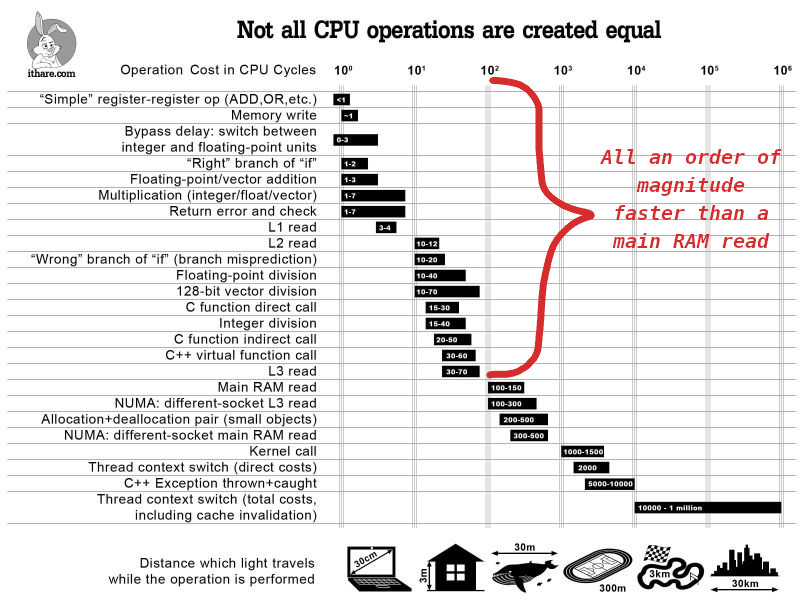
Notice that floating point division, something that we usually think of as an expensive operation, takes a tenth of the instructions as reading from main memory.
So while it is great yes, that pointers exist and function as we expect them too, they are not some silver bullet. What is probably the closest thing to a silver bullet however, are the different levels of cache and how they speed up memory reads.
Reading from memory only takes hundreds of cycles if the memory hadn’t already existed in an L1, L2, or L3 cache of your cpu. If the endgoal of writing performant and efficient programs is to minimize the work the cpu has to do, we should be taking note when most of that time is spent bussing data to and fro.
Therefore, if we care about performance, we must care about cache misses, and how the design and organization of our programs state affects them.
TO BE FINISHED ON A LATER DATE