
For some context, the parser that I’ve been writing produces a flat AST with indices instead of pointers. As a result, all AST nodes are stored in nodes buffer, with a separate extra data structure.
Our simplest choice is to use an ArrayList for our extra data structure, but what happens when you encounter nested expressions that are of arbitrary size?
The keen reader may realize, that if we were to naively push to our extra buffer item by item, there would be nothing stopping our subexpressions from pushing to extra in between our items, and suddenly our items are not contiguous. The next best solution, is to only append to extra once all the subexpressions have been parsed, but this requires us to store that data somewhere else in the meantime, and then @memcpy it to extra later.
By using an ArrayList and pushing with a general purpose allocator, we end up with code like this
fn parse_list() {
const gpa = GeneralPurposeAllocator();
const stat_list = ArrayList(Node).empty;
defer stat_list.free(gpa);
while (expr_to_parse) {
stat_list.append(parse_expr(), gpa);
}
parser.extra.appendSlice(stat_list.items)
}
There are many reasons this is non-ideal, but the most obvious is that the GPA is slow, and we call it every time we need to parse a list. malloc and new are the wrong tool for the job, they excel at large, batched allocations that are few in number. In contrast, we need many, small and frequent allocations (including reallocations).
Using an arena allocator comes with some benefits, such as cheaper allocation, deallocation that need only occur at the end of the arena’s lifetime, and improvements in cache locality. This improves our circumstances, but there is another issue that we have not yet solved. As items are pushed, reallocations occur, especially in the starting part of an ArrayList’s growth, which may lead to fragmentation,
Remember when I said most lists are of small size? Then we can just store it on the stack. Be lazy, and only use dynamic memory allocation when necessary. This is surprisingly flexible, and can get you where you need to go 90% of the time, but we can also be clever.
If you want a robust allocator, you have to figure out where to put the memory. A common practice is to keep a free list, but I opted instead to organize my data structure around the swap and pop deallocation strategy. It only works for objects of the same size stored contiguously in memory, and you usually keep a separate array to store metadata.
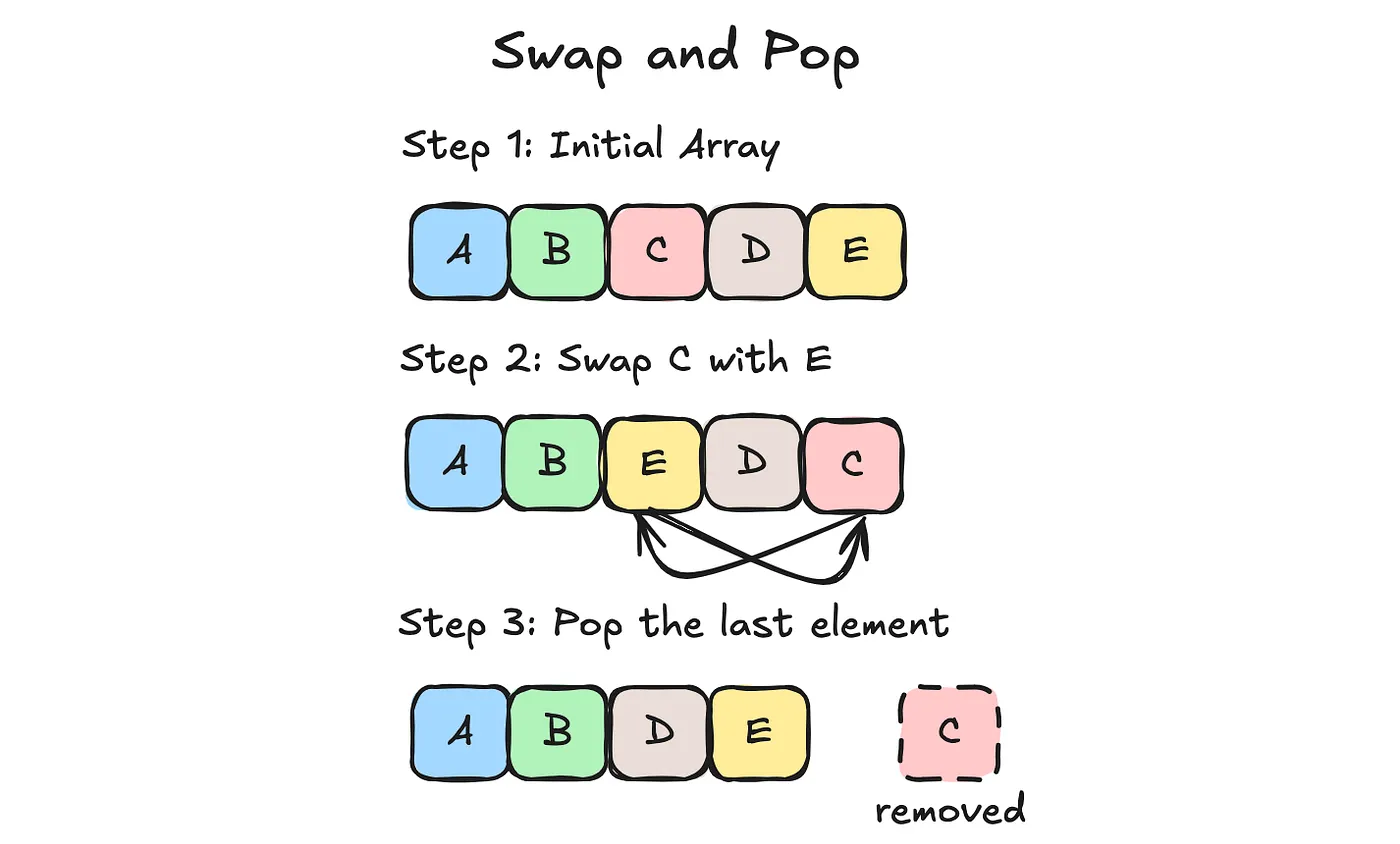
This is our underlying array, for which indices into whom are unstable. This visual doesn’t include what happens to our metadata array but before step 2, you access the metadata for C and find the metadata for E. As you swap the underlying memory, you also swap their metadata.
For all the benefits of LIFO allocating, you only have one choice of object to deallocate. Here, we traded memory stability for the benefits of LIFO allocation, namely O(1) deallocations with zero fragmentation. We can implement a wicked fast and simple memory pool this way.
This is where our problem before of storing many, dynamically resizable small lists comes into play. We can create buckets to sort our lists into, based on their capacity. This way, only lists of the same capacity are next to each other in memory, allowing for the same swap and pop shenanigans.
But how do we tell which buffer our data is in? Our metadata from earlier only held an index to the underlying buffer, but now we also need to store a length and a capacity. Reallocations amount to a new_bucket.appendSlice(items) and a @memmove(items, last_items) to fill in the newly duplicated items, to be followed by an old_bucket.items.len -= capacity.
Aside from the case of promoting to .arblists, there is little much to do.
I chose the fallback amount to be length 129, where allocation is deferred to a backing arena allocator.
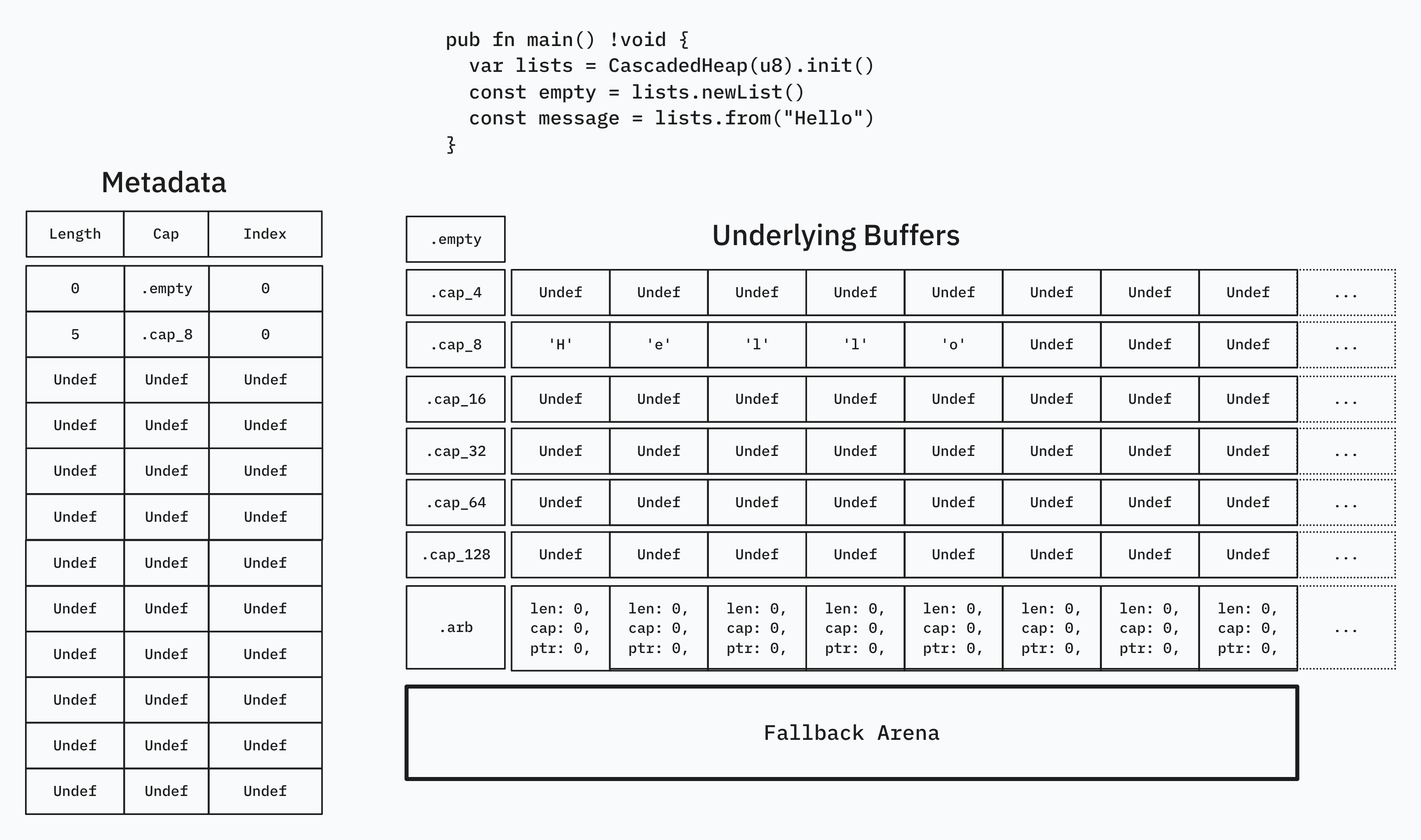
Our actual container looks something like this, with Item being generic:
struct {
subindices: ArrayList(SubIdx),
lengths: ArrayList(u32),
sublists: [7]ArrayList(Item),
arblists: ArrayList(ArrayList(Item)),
arena: std.heap.ArenaAllocator,
}
Our metadata is in .subindices in the form of the SubIdx struct, defined below.
const SubIdx = packed struct(u64) {
len: u8,
cap: Cap,
idx: u53,
const Cap = enum(u3) {
empty = 0,
cap_4 = 1,
cap_8 = 2,
cap_16 = 3,
cap_32 = 4,
cap_64 = 5,
cap_128 = 6,
arb = 7,
}
}
SubIdx.Cap is defined such that it can index into .sublists and return the correct buffer, to be sliced by the index and length. Notice that we only need a u8 to store the length, because anything above length 128 is allocated by arena.
I have the rest of the implementation on my codeberg, and have already started using it in my parser, storing other indices to other objects in u32 form. I’d like to write a follow-up article about how this makes serialization trivial, but for now I hope you learned something!