
I’ve been working on writing a recursive descent parser, and have decided to heavily use indices instead of pointers. As such, it was only natural for my parser to produce a flat AST.
For our purposes, all AST nodes will be stored in nodes buffer; We will also have an extra buffer that stores arbitrarily sized lists, mainly comprised of indices into the nodes buffer.
In most grammars, there are many cases where a parser must iterate to an arbitrary degree. This presents a challenge for how to store the results of these iterations when control flow is non-trivial.
The keen reader may realize that while parsing, if we were to naively push to our extra buffer item by item, there would be nothing stopping our subexpressions from pushing to extra in between our items, and suddenly they may be non-contiguous.
The next best solution, is to only append to extra once all the subexpressions have been parsed, but this requires us to store that data somewhere else in the meantime, and then @memcpy it to extra later.
By using an ArrayList and pushing with a general purpose allocator, we end up with code like this
fn parse_list() {
const gpa = GeneralPurposeAllocator();
const stat_list = ArrayList(Node).empty;
defer stat_list.free(gpa);
while (expr_to_parse) {
stat_list.append(parse_expr(), gpa);
}
parser.extra.appendSlice(stat_list.items)
}
There’s nothing particularly incorrect about this approach, but we have to ask if it is the most efficient tool we can reach for.
General purpose allocators excel at a wide variety of things, but if we know enough about what our data looks like, that generality may come at the cost of performance.
For our use case of many, small allocations, there are better options available.
Using an arena allocator comes with some benefits, such as cheaper allocation, deallocation that need only occur at the end of the arena’s lifetime, and improvements in cache locality.
Our strategy seems to have improved, but there is another issue that we have not yet solved. As items are pushed, reallocations occur, especially in the starting part of an ArrayList’s growth, which may lead to fragmentation.
This one won’t be the focus of the post, but I had to mention it by nature of its power and flexibility. Why use dynamic memory management if you don’t have to?
If we know most lists are at or below length 8, we can just push it to the call stack, and only allocate for larger lists. The flexibility comes from the fact that we can parameterize the length to whatever we please.
For now, let’s just imagine a simple bump allocator, with a pointer to a backing buffer, and an offset index. If we only ever used last-in-first-out semantics, we have the simplest form of an arena, a stack.
Because pointers need to be stable, the gaps in memory resulting from deallocations cannot be reorganized. The common solution to this is to keep track of free memory with a linked list.
However, if we give up the constraint of requiring our memory stay in-place, there is ample flexibility with how we can reorganize gaps in memory.
Behold, the swap and pop deallocation strategy. Before you deallocate an object, you swap it with the last value, and pop it from the buffer. Note that this allocation technique only works with fixed size values; But through these constraints and sacrifices, we have succeeded in eliminating fragmentation.
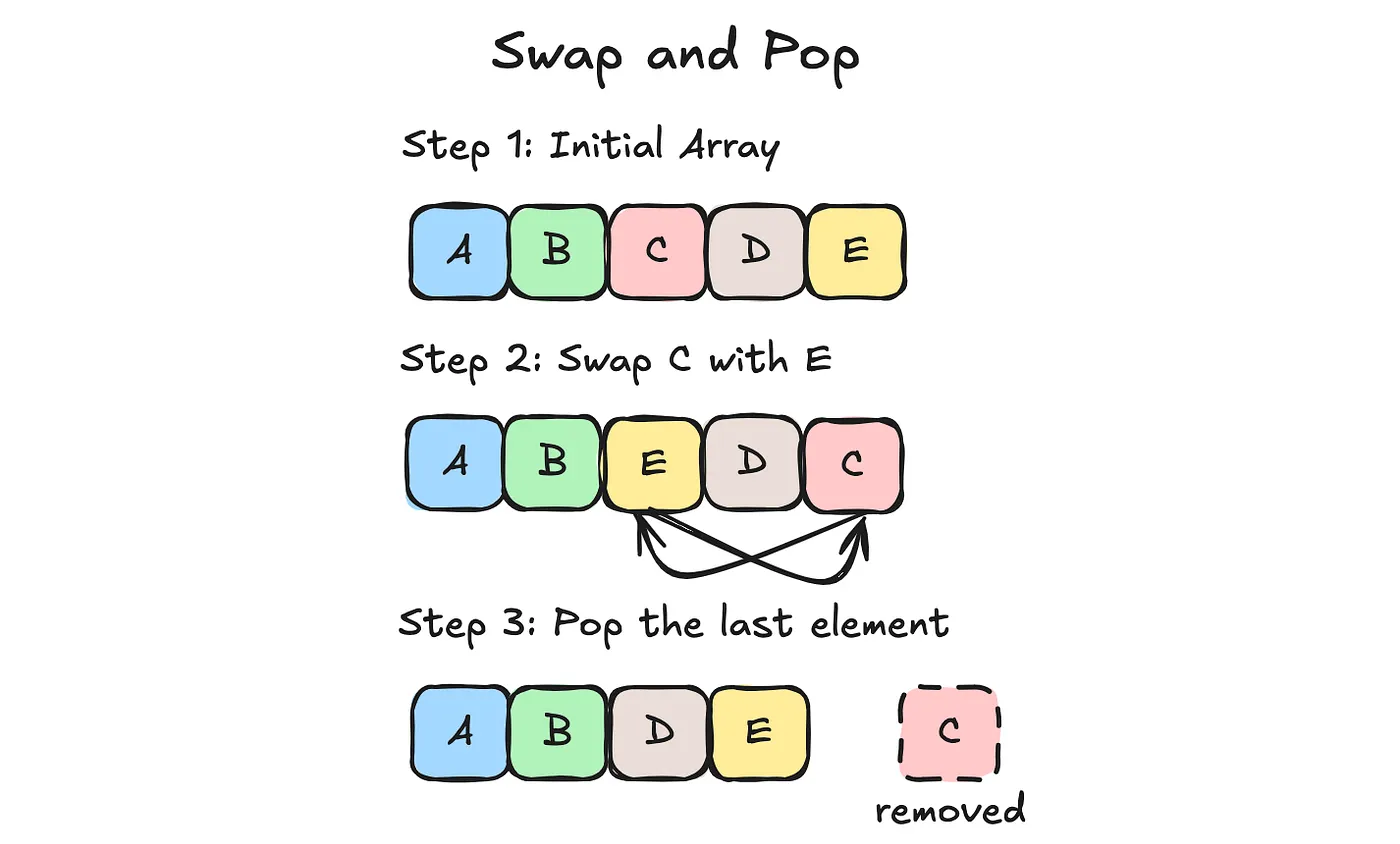
This is where our problem before of storing many, dynamically resizable small lists comes into play. We can create buckets to sort our lists into, based on their capacity. This way, only lists of the same capacity are next to each other in memory, allowing for the same swap and pop shenanigans.
In order to manage the metadata of these lists (index, length, capacity), we store them in a seperate metadata array, to be accesed by a stable u32 index.
As we push items to our many possible lists, some of their lengths will exceed their respective capacities, necessitating a reallocations.
How a reallocation occurs is by first allocating and copying the now full list into a larger bucket; Secondly, you perform a @memmove on the last array of the initial bucket, and overwrite the now duplicated data. Finally, you update the metadata of these arrays to index into their new addresses in memory.
Above length 128, allocation is deferred to a backing arena allocator.
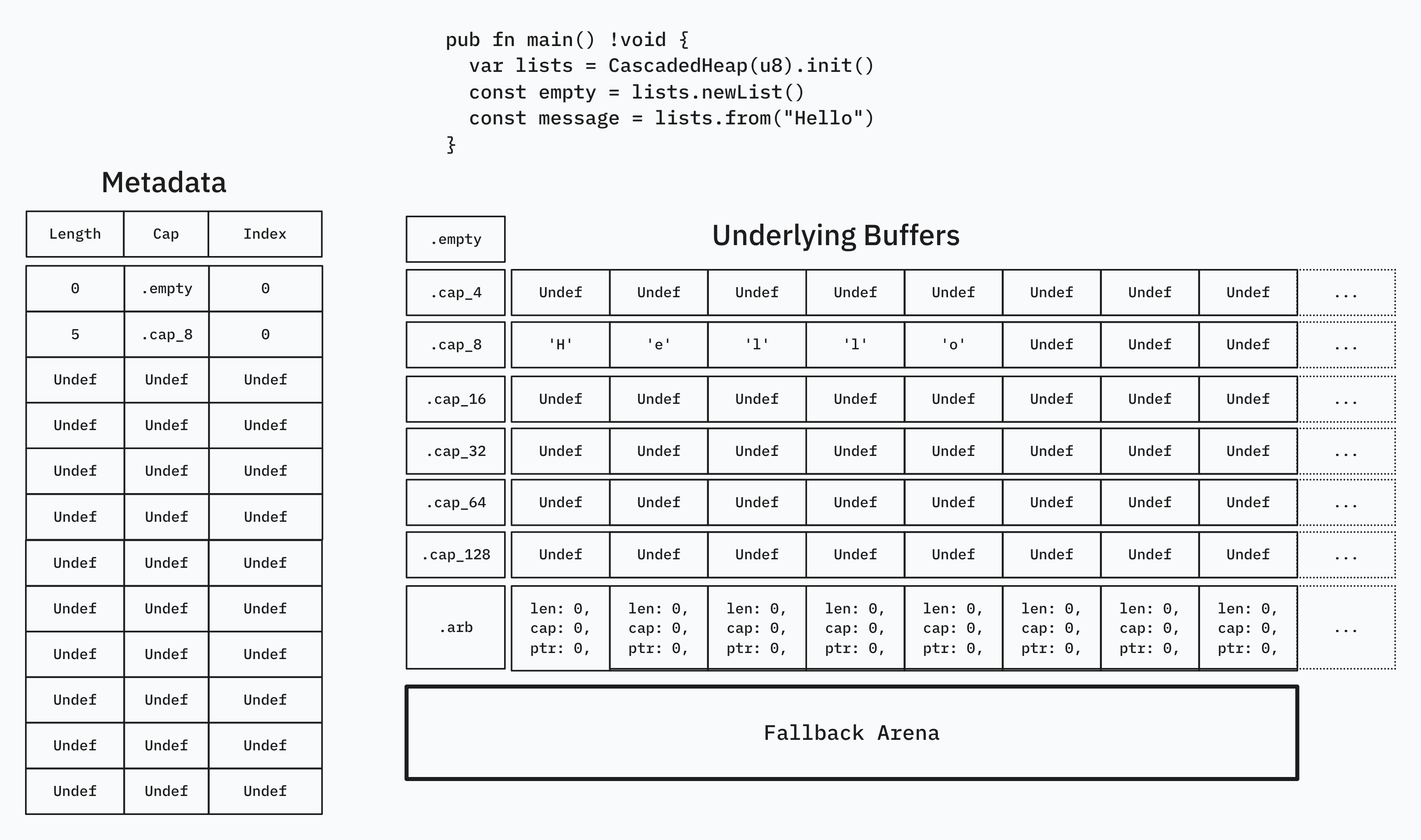
Our actual container looks something like this, with Item being generic:
struct {
subindices: ArrayList(SubIdx),
sublists: [7]ArrayList(Item),
arblists: ArrayList(ArrayList(Item)),
arena: std.heap.ArenaAllocator,
}
Our metadata is in .subindices in the form of the SubIdx struct, defined below.
const SubIdx = packed struct(u64) {
len: u8,
cap: Cap,
idx: u53,
const Cap = enum(u3) {
empty = 0,
cap_4 = 1,
cap_8 = 2,
cap_16 = 3,
cap_32 = 4,
cap_64 = 5,
cap_128 = 6,
arb = 7,
}
}
SubIdx.Cap is defined such that it can index into .sublists and return the correct buffer, to be sliced by the index and length. Notice that we only need a u8 to store the length, because anything above length 128 is allocated by arena.
I have the rest of the implementation on my codeberg.
If you want to see the reallocation logic, here it is in List.reserveSlice()
I’d like to write a follow-up article about serialization posibilities, but for now I hope you learned something!